Single-Node Chroma: Performance and Limitations
The single-node version of Chroma is designed to be easy to deploy and maintain, while still providing robust performance that satisfies a broad range of production applications.
To help you understand when single-node Chroma is a good fit for your use case, we have performed a series of stress tests and performance experiments to probe the system’s capabilities and discover its limitations and edge cases. We analyzed these boundaries across a range of hardware configurations, to determine what sort of deployment is appropriate for different workloads.
This document describes these findings, as well as some general principles for getting the most out of your Chroma deployment.
Results Summary#
Roughly speaking, here is the sort of performance you can expect from Chroma on different EC2 instance types with a very typical workload:
- 1024 dimensional embeddings
- Small documents (100-200 words)
- Three metadata fields per record.
| Instance Type | System RAM | Approx. Max Collection Size | Mean Latency (query) | 99.9% Latency (query) | Mean Latency (insert, batch size=32) | 99.9% Latency (insert, batch size=32) | Monthly Cost |
|---|---|---|---|---|---|---|---|
| r7i.2xlarge | 64 | 15,000,000 | 5ms | 7ms | 112ms | 405ms | $386.944 |
| t3.2xlarge | 32 | 7,500,000 | 5ms | 33ms | 149ms | 520ms | $242.976 |
| t3.xlarge | 16 | 3,600,000 | 4ms | 7ms | 159ms | 530ms | $121.888 |
| t3.large | 8 | 1,700,000 | 4ms | 10ms | 199ms | 633ms | $61.344 |
| t3.medium | 4 | 700,000 | 5ms | 18ms | 191ms | 722ms | $31.072 |
| t3.small | 2 | 250,000 | 8ms | 29ms | 231ms | 1280ms | $15.936 |
Deploying Chroma on a system with less than 2GB of RAM is not recommended.
Note that the latency figures in this table are for small collections. Latency increases as collections grow: see Latency and collection size below for a full analysis.
Memory and collection size#
Chroma uses a fork of hnswlib to efficiently index and search over embedding vectors. The HNSW algorithm requires that the embedding index reside in system RAM to query or update.
As such, the amount of available system memory defines an upper bound on the size of a Chroma collection (or multiple collections, if they are being used concurrently.) If a collection grows larger than available memory, insert and query latency spike rapidly as the operating system begins swapping memory to disk. The memory layout of the index is not amenable to swapping, and the system quickly becomes unusable.
Therefore, users should always plan on having enough RAM provisioned to accommodate the anticipated total number of embeddings.
To analyze how much RAM is required, we launched an an instance of Chroma on variously sized EC2 instances, then inserted embeddings until each system became non-responsive. As expected, this failure point corresponded linearly to RAM and embedding count.
For 1024 dimensional embeddings, with three metadata records and a small document per embedding, this works out to N = R * 0.245 where N is the max collection size in millions, and R is the amount of system RAM required in gigabytes. Remember, you wil also need reserve at least a gigabyte for the system’s other needs, in addition to the memory required by Chroma.
This pattern holds true up through about 7 million embeddings, which is as far as we tested. At this point Chroma is still fast and stable, and we did not find a strict upper bound on the size of a Chroma database.
Disk space and collection size#
Chroma durably persists each collection to disk. The amount of space required is a combination of the space required to save the HNSW embedding index, and the space required by the sqlite database used to store documents and embedding metadata.
The calculations for persisting the HNSW index are similar to that for calculating RAM size. As a rule of thumb, just make sure a system’s storage is at least as big as its RAM, plus several gigabytes to account for the overhead of the operating system and other applications.
The amount of space required by the sqlite database is highly variable, and depends entirely on whether documents and metadata are being saved in Chroma, and if so, how large they are. As a single data point, the sqlite database for a collection with ~40k documents of 1000 words each, and ~600k metadata entries was about 1.7GB.
There is no strict upper bound on the size of the metadata database: sqlite itself supports databases into the terabyte range, and can page to disk effectively.
In most realistic use cases, it’s likely that the size and performance of the HNSW index in RAM becomes the limiting factor on a Chroma collection’s size long before the metadata database does.
Latency and collection size#
As collections get larger and the size of the index grows, inserts and queries both take longer to complete. The rate of increase starts out fairly flat then grow roughly linearly, with the inflection point and slope depending on the quantity and speed of CPUs available. The extreme spikes at the end of the charts for certain instances, such as t3.2xlarge, occur when the instance hits its memory limits.
Query Latency
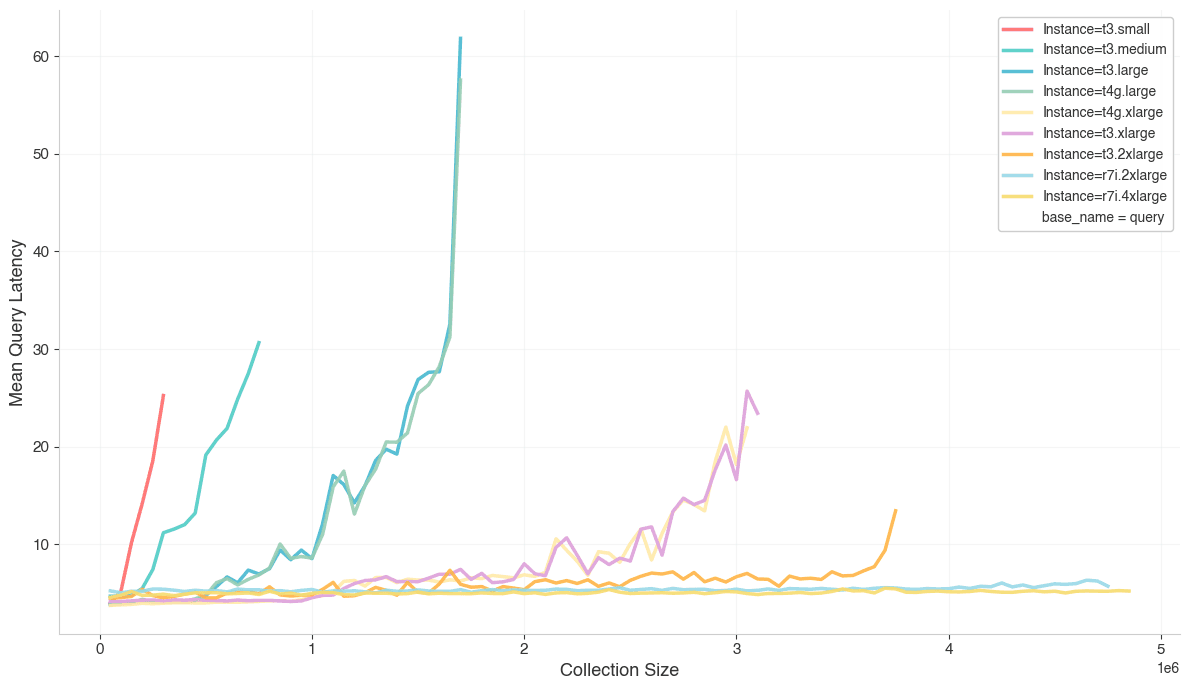
Insert Latency

If you’re using multiple collections, performance looks quite similar, based on the total number of embeddings across collections. Splitting collections into multiple smaller collections doesn’t help, but it doesn’t hurt, either, as long as they all fit in memory at once.
Concurrency#
The system can handle concurrent operations in parallel. For inserts, since writes are written to a log and flushed every N operations, the mean latency does not fluctuate as the number of writers increases, but does increase as batch size increases since larger batches are more likely to hit the flush threshold. The queries parallelize up to the number of vCPUs available in the instance, after which it begins queueing, thus causing a linear increase in latency.


See the Insert Throughput section below for a discussion of optimizing user count for maximum throughput when the concurrency is under your control, such as when inserting bulk data.
CPU speed, core count & type

Insert Throughput
A question that is often relevant is: given bulk data to insert, how fast is it possible to do so, and what’s the best way to insert a lot of data quickly?
The first important factor to consider is the number of concurrent insert requests.
As mentioned in the Concurrency section above, insert throughput does benefit from increased concurrency. A second factor to consider is the batch size of each request. Performance scales with batch size up to CPU saturation, due to high overhead cost for smaller batch sizes. After reaching CPU saturation, around a batch size of 150 the throughput plateaus.
Experimentation confirms this: overall throughput (total number of embeddings inserted, across batch size and request count) remains fairly flat between batch sizes of 100-500:

Given that smaller batches have lower, more consistent latency and are less likely to lead to timeout errors, we recommend batches on the smaller side of this curve: anything between 50 and 250 is a reasonable choice.
Conclusion#
Users should feel comfortable relying on Chroma for use cases approaching tens of millions of embeddings, when deployed on the right hardware. It’s average and upper-bound latency for both reads and writes make it a good platform for all but the largest AI-based applications, supporting potentially thousands of simultaneous human users (depending on your application’s backend access patterns.)
As a single-node solution, though, it won’t scale forever. If you find your needs exceeding the parameters laid out in this analysis, we are extremely interested in hearing from you. Please fill out this form, and we will add you to a dedicated Slack workspace for supporting production users. We would love to help you think through the design of your system, whether Chroma has a place in it, or if you would be a good fit for our upcoming distributed cloud service.